
Really enjoyed reading about the different ways we're attacking the agentic memory problem. Though, through building my own solution, I realized we are understating the value of compute as the bedrock.
A short walkthrough of what I mean, with the actual math.
- Retrieval Via Computation
- Learning
- Forgetting
- Environment Building
We're treating LLMs as the entire car
As a community, we've fallen into the trap of unnecessary abstraction. We consistently think of LLMs as the entire car: the wheels, the engine, the body, everything.
We're using probabilistic, emergent algorithms for tasks that should be deterministic. The new thing is still a shiny toy to us, and we're just using it whenever, getting drunk on its potential.
LLMs are the wrong substrate for memory
Even with radical improvement, models can never replicate tasks cleanly, no matter the harness, no matter the tools, nor the system prompt. Because of their predictive nature, they'll always hallucinate.
There is nothing they're tied to tangibly, thus it doesn't make sense to use them for things that benefit from routine, deterministic behavior, such as the foundations of agentic memory: retrieval, context injection, etc.
The LLM part of an agent should never be tasked with carrying the stack from beginning to end.
Ori Mnemos — an experiment in computation-powered agentic cognition
github.com/aayoawoyemi/Ori-Mnemos
Through my research and musings, I hold the belief that we should model agentic cognition the same way a plane models a bird. And even more so than this, we should be building an environment, a deterministic environment, for the LLMs to traverse.
There are a lot of things we have naturally solved in the realm of memory, through countless years of evolution. We can take these conceptual frameworks and apply them in a mechanical manner, rather than trying to start with the mechanics and branch out.
Ori Mnemos is my experimentation with that philosophy. My first public GitHub repo, it is a local-source, decentralized memory framework that has outperformed Mem0 on LoCoMo.
For the rest of this article, I'll go through the different layers that make up this framework and the hard numbers of the computation that becomes the bedrock for my agentic layers to run freely, effectively, and efficiently.
1 — Retrieval via computation
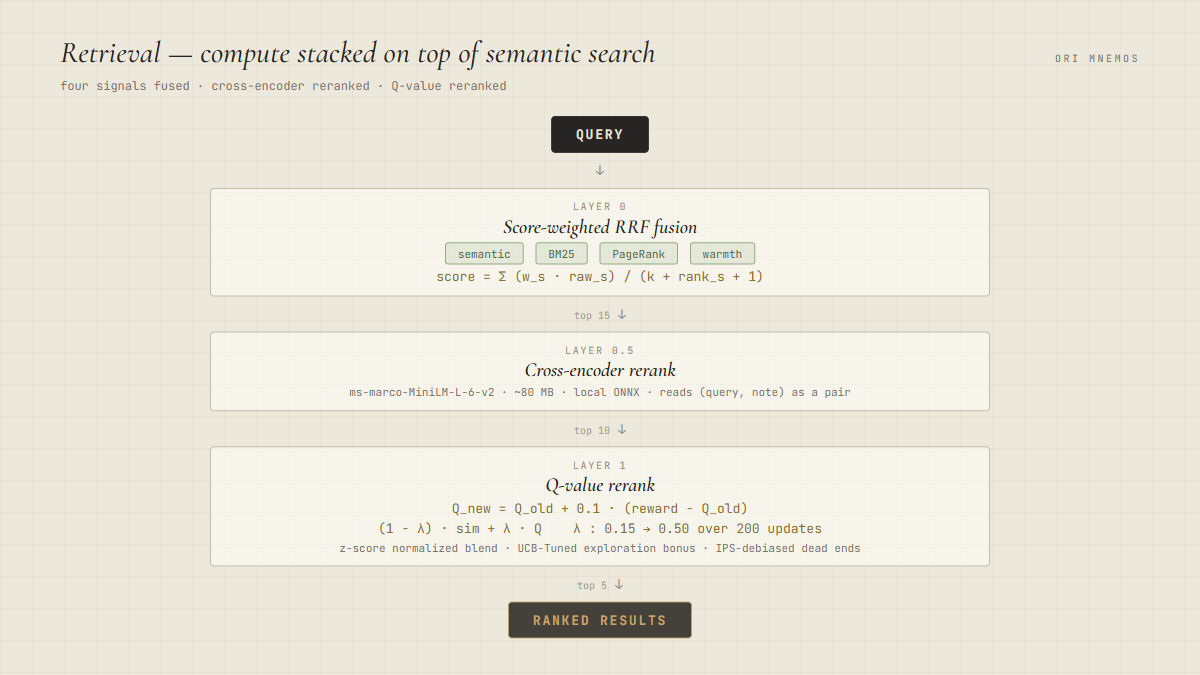
Rather than relying on pure semantic search, Ori's first layer is score-weighted Reciprocal Rank Fusion across four signals:
- dense semantic similarity
- BM25 keyword
- personalized PageRank on the wiki-link graph
- warmth
Each signal contributes a rank-discounted vote, and all four fuse into a single ranked list.
score(note) = Σ_s (w_s × raw_score_s) / (k + rank_s + 1)On top of that, a small model: a cross-encoder reranker. ms-marco-MiniLM-L-6-v2, 80MB, local ONNX. It reads the query and the note together as a pair and scores the relationship. Top 15 gets cut to top 10, for roughly 15 to 20 percent absolute MRR improvement.
2 — Learning via computation
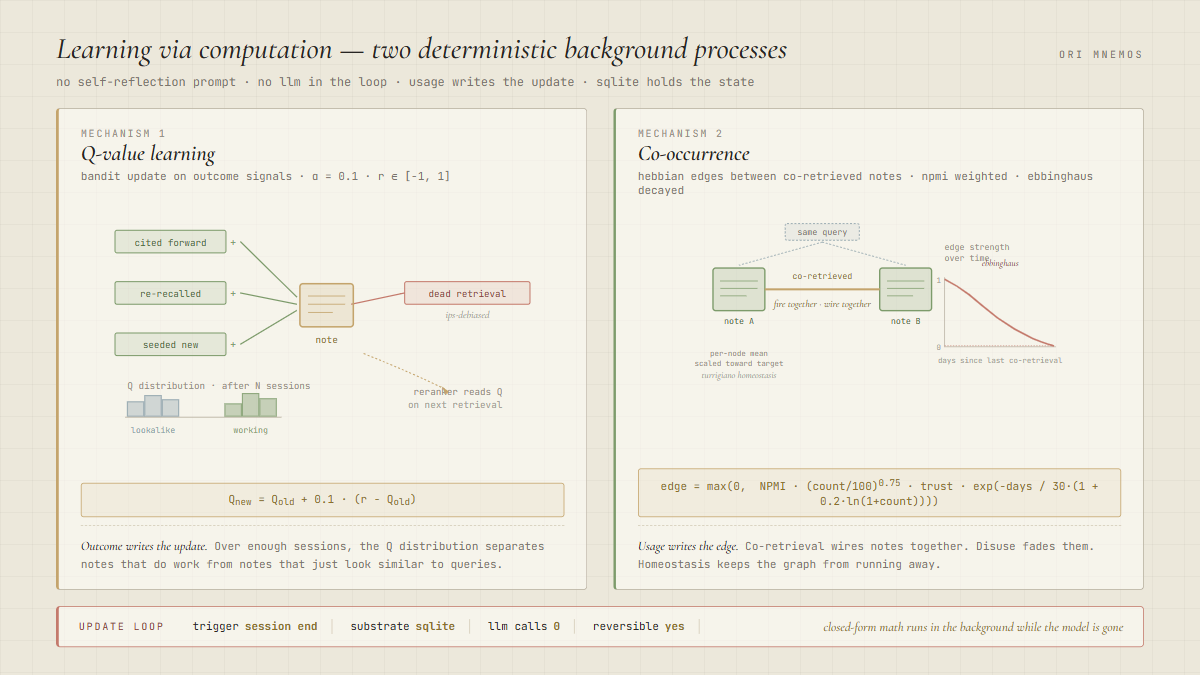
The current landscape handles learning by asking the LLM to reflect on what happened. After a conversation or task, the model evaluates itself.
A probabilistic system is assessing its own performance and deciding what it learned, which means every learning event inherits the same uncertainty the system is trying to correct.
Ori has two deterministic mechanisms running in the background.
A) Q-value learning
When a retrieved note earns a forward citation, gets re-recalled in a later session, or seeds a new note, it earns reward. When a note gets retrieved in the top results and then goes nowhere, it earns negative reward, IPS-debiased so the system doesn't punish exploration. Plain bandit update at session end:
Q_new = Q_old + 0.1 × (reward − Q_old)α = 0.1. Reward range [-1, 1]. Over enough sessions, the Q distribution separates notes that actually do work from notes that just look similar to queries. The reranker reads that Q on the next retrieval.
B) Co-occurrence
When two notes come back in the same query result, Ori records a co-retrieval event between them. The edge weight is an NPMI score (normalized pointwise mutual information), scaled by GloVe-style frequency weighting and decayed on an Ebbinghaus curve:
edge = max(0, NPMI × (count / 100)^0.75 × trust × exp(-days / 30·(1 + 0.2·ln(1+count))))Neurons that fire together wire together.
Closed-form math running on actual usage, powering the learning mechanism of Ori. All before a single LLM call.
3 — Forgetting via computation
Forgetting has been one of the hardest nuts to crack, and too many of the frontier labs are continually treating memory as a storage problem. Over time, even an extremely well-designed memory system will accumulate noise, making it near impossible to iterate through an inherently broken system: finding a needle in an increasingly larger, increasingly growing haystack.
There are two main LLM-only approaches, and both fail.
The first is indefinite accumulation, followed by blind hope that iteration on LLM-based retrieval is enough to compensate.
The second is asking the LLM to decide what to keep or delete. Once again, a probabilistic system making irreversible decisions about what information to permanently discard. Empirically, this causes self-degradation.
Ori forgets with spreading activation plus usage-aware Ebbinghaus decay
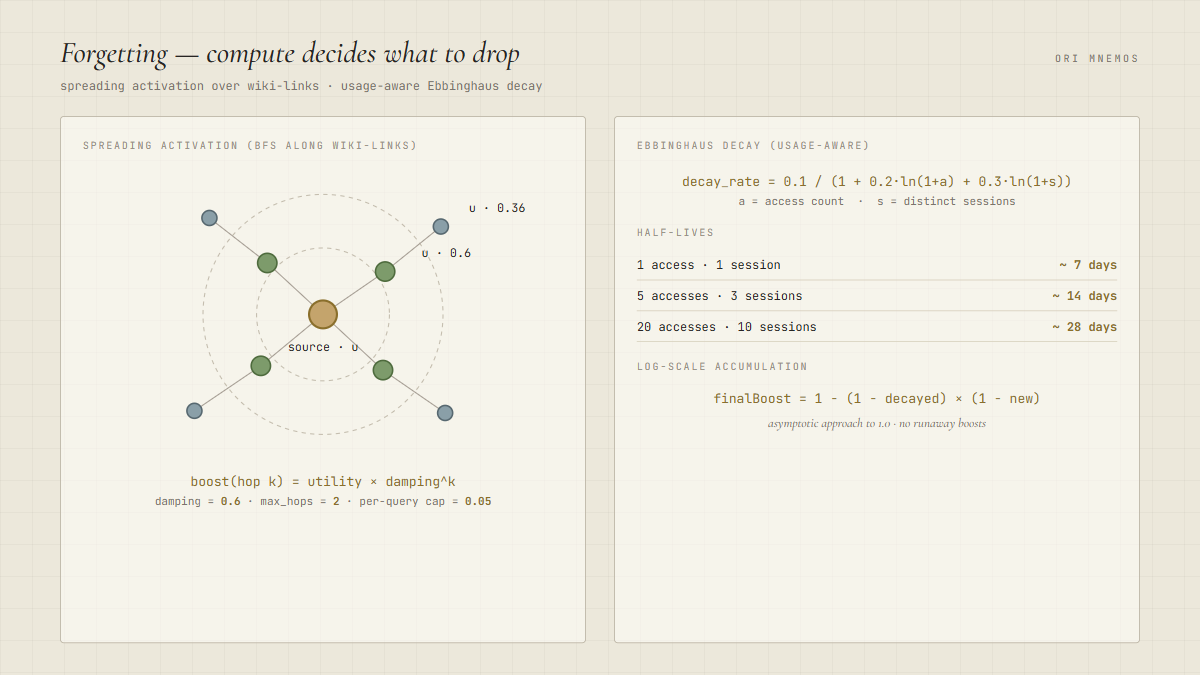
When a note is retrieved, a boost propagates outward through the wiki-link graph via BFS. The boost fades with distance:
boost(neighbor at hop k) = utility × damping^kThe parameters: damping 0.6, max hops 2, per-query cap 0.05. Boosts accumulate log-scale toward an asymptote of 1.0, so no single note runs away:
finalBoost = 1 − (1 − decayedExisting) × (1 − newBoost)Then the actual decay. Every boost fades at a rate shaped by how often the note is accessed and how many distinct sessions it shows up in:
decay_rate = 0.1 / (1 + 0.2·ln(1+accesses) + 0.3·ln(1+sessions))- 1 access · 1 session — half-life ~7 days
- 5 accesses · 3 sessions — half-life ~14 days
- 20 accesses · 10 sessions — half-life ~28 days
4 — How compute turns the vault into an environment

Declarative tool calling is the current meta. The model is encouraged and allowed to fire a request, get a blob back, stuff it in context, and passively wait for the next injection.
The shift is from giving the AI tools to giving it an environment. Cognition, and thus memory, becomes a space the agent traverses.
With an environment, the model walks into the library/vault itself, reads the catalog, pulls a book off the shelf, skims it, makes a note, and goes back with a sharper question. The context stays clean the entire time. Only the final answer is injected.
Shout out to @a1zhang and his RLM paper for inspiring the Recursive Memory Harness (RMH), a framework that turns the vault of memories into a Python body, spoken to over JSON-RPC on stdin/stdout. It forces the model to operate in three ways:
- Retrieval must follow the graph. When a note is retrieved, activation propagates along its edges. The system cannot return isolated results. It returns clusters of related knowledge.
- Unresolved queries must recurse. When a retrieval pass doesn't fully resolve the query, the system generates sub-queries targeting what's missing. Each enters the graph from new entry points and runs its own pass. When new relevant information stops being found, the system stops.
- Every retrieval must reshape the graph. When a note is accessed, connected notes within two hops receive a vitality boost that decays with distance. Notes never retrieved or cited decay on an Ebbinghaus curve. The graph is not allowed to be static.
The core primitive is rlm_call(slice, sub_question). It spawns a fresh sub-LLM with a focused slice of the vault and a single sub-question, and returns the answer back to the outer REPL as a plain Python value the parent code can branch on, filter, or accumulate.
This is the one place the LLM is actually in the loop. And even here, compute sets the rails. Every bound is enforced before the model writes a line of Python:
- Max 15 sub-calls per top-level exec. Explicit counter, prevents runaway cost.
- Max 5 in flight at once. Asyncio semaphore in
rlm_batch. - Depth is 1, enforced architecturally. The sub-call gets a single user turn with no tools, no REPL, no
rlm_call. Its response comes back as a string. Data, not code. Recursion cannot escape one level.
Why computation wins in each layer
LLMs are good at extraction, but they are inherently prone to hallucination. There are certain things we have already solved in technology, and they are built on deterministic, repeatable workflows. Trying to replace those workflows with prediction-based algorithms is not only a waste of tokens, it is not effective.
COMPUTATION IS THE BEDROCK.